在進行資料分析的過程中,我們經常需要從龐大的資料集中提取特定的子集,這時候篩選和切片是非常重要的技能。今天,我們將學習如何根據條件篩選資料以及如何使用切片操作來提取需要的資料子集。
依樣在同一個資料夾,開啟一個新的 Google Colab 筆記本,檔名叫做 Iris_loc。
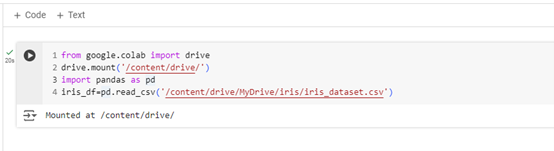
首先,我們繼續使用 Iris 資料集,並將其讀取到 Pandas 資料框中。
from google.colab import drive
drive.mount('/content/drive/')
import pandas as pd
# 讀取 CSV 檔案
iris_df = pd.read_csv('/content/drive/MyDrive/iris/iris_dataset.csv')
我們可以根據條件篩選資料集中的特定資料。例如,篩選出所有花萼長度大於 5.0 的資料:
# 篩選出花萼長度大於 5.0 的資料
filtered_df = iris_df[iris_df['sepal length (cm)'] > 5.0]
# 顯示篩選後的資料集
print(filtered_df.head())
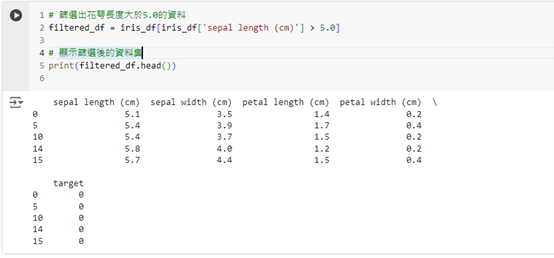
這段程式碼篩選出 sepal length (cm) 大於 5.0 的所有資料行。
我們還可以使用多重條件來篩選資料。例如,篩選出花萼長度大於 5.0 且花瓣寬度小於 1.5 的資料:
# 使用多重條件篩選
filtered_df = iris_df[(iris_df['sepal length (cm)'] > 5.0) & (iris_df['petal width (cm)'] < 1.5)]
# 顯示篩選後的資料集
print(filtered_df.head())
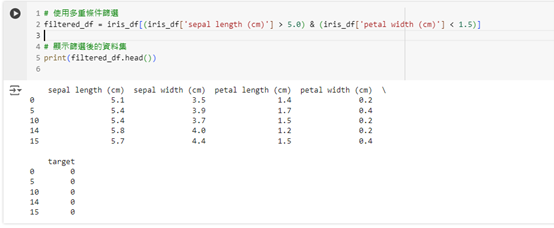
這段程式碼將返回符合這兩個條件的資料行。
.loc[] 進行切片Pandas 提供了 loc[] 函數,可以根據行標籤和列標籤來提取資料。範例中我們將提取前 10 筆資料並只顯示花萼長度和花瓣長度:
# 使用 loc[] 進行資料切片
subset_df = iris_df.loc[0:9, ['sepal length (cm)', 'petal length (cm)']]
# 顯示切片後的資料集
print(subset_df)
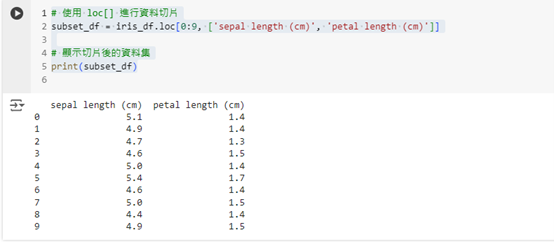
這樣可以只顯示指定的資料範圍和列。
.iloc[] 進行切片iloc[] 是用來根據數字索引來提取資料的工具。這個範例中我們提取前 10 筆資料,並顯示第一列和第三列的數據:
# 使用 iloc[] 進行資料切片
subset_df = iris_df.iloc[0:10, [0, 2]]
# 顯示切片後的資料集
print(subset_df)
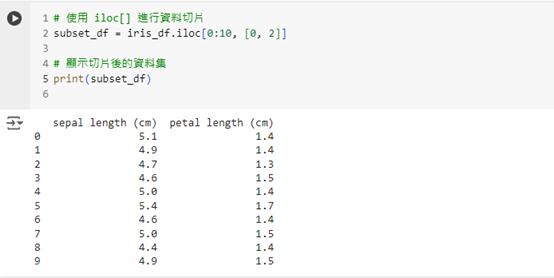
這段程式碼將使用數字索引提取資料,0:10 代表行的範圍,[0, 2] 代表列的索引。
今天我們學習了如何使用 Pandas 進行資料的篩選與切片操作,包括:
loc[] 與 iloc[] 進行資料切片這些技巧是資料分析中非常常用的操作,能夠幫助我們快速提取所需的資料。接下來,我們將學習資料型態轉換與處理。


 iThome鐵人賽
iThome鐵人賽